Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Graph traversal systematically visits vertices. Depth‑First Search dives deeply along paths; Breadth‑First Search expands layer by layer. Built‑ons like topological sort and component detection exploit these passes to order DAGs and expose connectivity.
Graph traversal is the process of visiting each vertex in a graph in a systematic way. In other words, it means exploring the graph’s nodes and edges to discover all reachable vertices. Traversal algorithms ensure every vertex is visited exactly once (in some order), which is fundamental for analyzing graph structures. This matters because many higher-level graph problems (like searching for specific nodes, checking connectivity, or finding paths) rely on efficient traversal as a building block.
Graphs come in different types, and the traversal methods apply to all of them with slight considerations. A graph can be undirected (edges have no direction) or directed (edges have a direction, like one-way links). In directed graphs, a traversal from a given start node will only follow edges along their direction, which can restrict reachability compared to an undirected graph. Graphs may also be unweighted (all edges treated equally) or weighted (each edge has a numerical weight or cost). Traversal algorithms like DFS and BFS typically ignore weights (they just explore connectivity), whereas pathfinding algorithms take weights into account (e.g. Dijkstra’s algorithm for shortest paths in weighted graphs). In this article we focus on unweighted graph traversal; weighted pathfinding is covered separately.
The two core strategies for graph traversal are Depth-First Search (DFS) and Breadth-First Search (BFS). These form the basis for many graph algorithms. We will also discuss related algorithms built on traversal concepts: topological sorting (ordering nodes in directed acyclic graphs) and finding connected components (identifying isolated subgraphs, including strongly connected components in directed graphs). Each section includes how the algorithm works, real-world use cases, and pseudocode or step outlines where appropriate. The tone is tutorial-like but technically precise, similar in completeness and formality to our earlier sorting and searching articles.
This article is part of a comprehensive guide about algorithms. To access the main article and read about other types of algorithms, from sorting to machine learning, follow the following link:
A Friendly Guide to Computer Science Algorithms by Category.
Depth-First Search (DFS) is a traversal algorithm that explores as far down one branch of the graph as possible before backtracking. In DFS, when you visit a vertex, you immediately continue to an unvisited neighbor of that vertex, then to an unvisited neighbor of that neighbor, and so on. You only backtrack when you reach a vertex that has no unvisited neighbors. This depth-first strategy means child vertices are visited before sibling vertices. Conceptually, it’s like walking through a maze by always taking the next unexplored corridor until you hit a dead end, then retracing your steps.
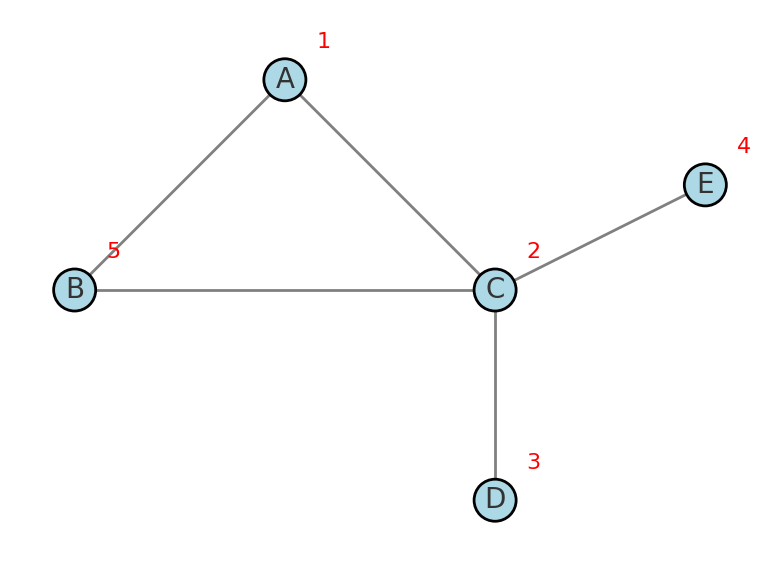
How it works: DFS can be implemented recursively or iteratively. The recursive version naturally uses the call stack to remember the path, whereas the iterative version uses an explicit stack data structure to simulate recursion. In both cases, the algorithm marks each vertex as visited when first encountered, to avoid processing it multiple times (which is especially important if the graph has cycles). Starting from a chosen root vertex, DFS proceeds as follows:
Using a stack (either implicit via recursion or explicit) ensures that the most recently discovered vertex that still has unexplored neighbors is processed next. The time complexity of DFS is O(V + E) (where V is the number of vertices and E is the number of edges) because in the worst case it will explore every vertex and every edge once.
Applications of DFS: DFS is a versatile algorithm used in many scenarios:
Real-world use cases of DFS include analyzing networks (e.g. finding clusters of connected users in a social network), performing searches in AI (like brute-force searches in problem-solving), and even tasks like web crawling (where one might follow links deeply before backtracking). Its memory footprint is typically lower than BFS for wide graphs, since it stores only a path at a time (O(V) in the worst case depth). However, DFS can get stuck going deep in one part of a graph; if the graph is infinite or extremely large in one branch, a naive DFS might not find solutions that lie in other branches. To mitigate that, variants like iterative deepening DFS impose depth limits.
Understanding Graph based search is an invaluable skill when dealing with Graph-based algorithms. Learn more about these techniques and algorithms following this link: Graph-Based Search Algorithms.
Breadth-First Search (BFS) is a traversal algorithm that explores the graph level by level. It starts at a given source vertex and first visits all neighbors of that vertex, then all the neighbors of those neighbors, and so on, expanding outward in waves. This approach ensures that vertices are visited in order of increasing distance from the start node (in terms of number of edges). In other words, BFS visits sibling vertices before moving to the next level of children.
How it works: BFS uses a queue to manage the frontier of exploration. The algorithm can be outlined as follows:
v. Visit v (process it) and then for each unvisited neighbor of v, mark it visited and enqueue it.Because BFS visits nodes in increasing order of distance from the source, it naturally finds the shortest path in an unweighted graph from the start node to any other reachable node. The first time you encounter a node in BFS, you have used the fewest edges possible to reach it. This makes BFS ideal for certain routing and distance problems. Like DFS, BFS runs in O(V + E) time with an adjacency list representation, since every vertex and every edge is processed once. However, BFS’s memory usage can be higher in breadth (it may store an entire level of nodes in the queue at once, which in a worst-case dense graph could be O(V) nodes).
Applications of BFS:
One key property of BFS is that it is complete (if there is a path from the start node to a goal node, BFS will definitely find it, and find the shortest such path). This is in contrast to DFS, which could potentially go down an infinite path and fail to find a reachable goal if not carefully managed. Because of this, BFS is often used in scenarios where finding the optimal solution (minimal steps) is more important than memory usage, whereas DFS might be chosen for scenarios where the search space is large but solutions are dense and one just needs a solution (not necessarily the shortest) with less overhead.
Topological sorting is an ordering of the vertices of a directed graph such that every directed edge (u → v) goes from an earlier vertex u to a later vertex v in the order. In other words, it’s a linear sequence of the graph’s nodes where each node comes after all of its prerequisites. Topological sort only applies to directed acyclic graphs (DAGs) – if there is a cycle, no valid topological order exists (you can’t order tasks if there’s a circular dependency). A classic example is a set of tasks with dependencies: if task X depends on task Y, then Y must appear before X in the ordering. A topological sort provides a schedule that respects all such constraints. Every DAG has at least one valid topological ordering, and in fact many DAG-related problems (like scheduling or determining compilation order) rely on computing this order.
There are two common algorithms to perform topological sorting: one based on DFS and another using Kahn’s algorithm (which uses a form of BFS). Both algorithms run in linear time O(V + E). We will describe each approach:
One way to generate a topological sort is to leverage Depth-First Search. The idea is to do a DFS traversal and take advantage of the natural backtracking order of DFS. When DFS explores a node, it recursively explores all that node’s descendants (outgoing edges) before marking the node as finished. If we record nodes in the reverse order of when they finish (i.e. push each node onto a stack when its DFS call is complete), we obtain a topological ordering.
A DFS-based topological sort algorithm typically works like this:
During this DFS, one must detect cycles: if a back edge is encountered (meaning we found an edge to a vertex that is in the current recursion stack, i.e. temporarily marked), then the graph has a cycle and a topological sort is impossible. In implementation terms, you might use three states for each node: unvisited, visiting (in recursion stack), and visited. If you ever try to visit a “visiting” node, you detected a cycle. Otherwise, the order in which nodes are added to the output list (a node is added after exploring its neighbors) ensures that each node comes before any nodes that depend on it. This approach is described in algorithms texts (such as the one by Cormen, Leiserson, Rivest, and Stein) and was originally published by Tarjan in 1976.
Use cases: Topological sorting via DFS is useful when you want to both detect cycles and produce an order. For instance, if you need to determine a valid build order of software components and also warn if there’s a cyclic dependency, a DFS-based solution can do both in one pass. In coding, one might implement this with recursion and a stack easily. However, care must be taken with recursion depth if the graph is large (to avoid stack overflow in languages without tail recursion optimization).
Kahn’s algorithm is an alternative that uses a breadth-first approach to produce a topological order. This algorithm explicitly computes in-degrees (the number of incoming edges) of vertices and repeatedly removes nodes with zero in-degree. The procedure for Kahn’s algorithm is:
n from the queue and add n to the topological order list. For each neighbor m of n (for each edge n → m), decrement the in-degree of m (because we are effectively “removing” the edge n → m from the graph). If any neighbor’s in-degree becomes 0, add that neighbor to the queue.Kahn’s algorithm will produce a topological order (not necessarily unique) for the DAG or report that none exists if a cycle is detected. It essentially peels the graph layer by layer: first all nodes with no incoming edges, then those whose prerequisites are all satisfied, and so on.
Use cases: Kahn’s method is intuitive for scenarios like scheduling. For example, consider course prerequisites: initially, take all courses with no prerequisites (in-degree 0). Those can be taken first. Once those are “removed,” some courses that had those as prerequisites now have one fewer prerequisite remaining; when some course’s prerequisites count drops to zero, it becomes available. This is exactly how Kahn’s algorithm would schedule courses. The algorithm cleanly separates the concern of cycle detection (if something’s left with in-degree > 0 at the end, you have a cycle in prerequisites). In practice, this approach is often used in systems that explicitly manage dependency counts – for instance, build systems (Make, etc.) or task schedulers might use a variant of this. One advantage of Kahn’s algorithm is that it doesn’t use recursion, so it can be easier to implement in an iterative environment and potentially can be adapted to handle dynamically added nodes (though in that case you’re really dealing with online scheduling).
Both DFS-based and Kahn’s algorithm achieve the same result: an ordering of nodes that respects all directed edges. It’s worth noting that if the graph has multiple valid topological orders, different algorithms (or different choices within the algorithms, like which zero in-degree node to pick first) may produce different orders. That’s fine as long as the partial order constraints are satisfied.
In many graphs, especially undirected ones, the graph may not be fully connected – it can consist of multiple separate clusters of vertices with no paths between them. Each such cluster is called a connected component. In an undirected graph, a connected component is a set of nodes where each node is reachable from any other node in that set (by some path). If an undirected graph has multiple connected components, no traversal starting from one component will ever reach another, so it’s often necessary to identify all components by restarting a traversal on unvisited nodes as needed. In directed graphs, we distinguish between general connectivity and strong connectivity. A strongly connected component (SCC) is a subset of vertices in a directed graph such that every vertex in the subset can reach every other vertex in the subset (each node is mutually reachable). This is a stricter condition – for instance, in a directed graph of web pages, an SCC would be a set of pages where each page has a path to every other (a strongly interconnected cluster of sites). Identifying connected components (undirected) or strongly connected components (directed) is a common task, useful for understanding the structure of networks and simplifying graphs by treating components as single units.
For an undirected graph, finding connected components is straightforward with either DFS or BFS. You can start a DFS/BFS from an unvisited node, mark all nodes reachable from it, that set of nodes forms one connected component. Then you pick another unvisited node (if any) and repeat, which yields another component, and so on. The algorithm ensures that each vertex is assigned to exactly one component. The result is typically a partition of the vertex set into disjoint components.
Example: Suppose you have a friendship network where each node is a person and edges represent friendship. The connected components of this graph would correspond to isolated friend groups (nobody in one group knows anyone in another group). By running a DFS or BFS from each person who hasn’t been placed in a group yet, you can discover all such friend circles. This has real-world use in social network analysis for finding communities.
The complexity is O(V + E) for finding all components, since essentially it is performing a full traversal of the graph (visiting each edge and vertex once). Many graph algorithms begin by finding connected components as a preprocessing step – for example, if you want to check some property in each independent section of a graph or run a heavy computation on each component separately.
In directed graphs, connectedness is not symmetric; one can have two vertices A and B where A can reach B but B cannot reach A. For strong connectivity, we require mutual reachability. The strongly connected components (SCCs) of a directed graph form a partition of the graph’s vertices (each vertex belongs to exactly one SCC), and if we contract each SCC into a single “super-node,” the resulting graph (called the component graph or condensation) is a DAG. Finding SCCs is important in many applications – for example, in dependency graphs, an SCC might indicate a set of interdependent tasks that form a cycle; in program analysis, SCCs of a call graph can identify groups of functions with mutual recursion.
There are two classic linear-time algorithms for finding all SCCs in a directed graph: Kosaraju’s algorithm and Tarjan’s algorithm. Both run in O(V + E) time.
Kosaraju’s Algorithm: This method uses two passes of DFS:
The rationale is that in the original DFS, we get a sort of ordering of influence (finish time order). Reversing edges and exploring in that order ensures that we jump into the “heads” of each SCC first. Nodes that are strongly connected will end up adjacent in the finish time ordering and will be grouped together in the second pass. Kosaraju’s algorithm is straightforward to understand and implement (essentially two DFS runs), though it does the work of DFS twice.
Tarjan’s Algorithm: Tarjan’s algorithm finds SCCs in one DFS pass. It was invented by Robert Tarjan and is a bit more intricate, using a single DFS with a stack and some bookkeeping:
u, it means u and all nodes on top of u in the stack up to itself form one SCC. The algorithm will pop the stack until it has removed u and all nodes above it, which yields the full component. Those nodes are then marked as having their SCC found, and the DFS continues.Tarjan’s algorithm is efficient and slightly more complex to implement, but it has the advantage of not needing a second pass or an explicit graph transpose. It directly identifies components on the fly.
Applications of SCCs: Finding SCCs in directed graphs has numerous applications. In compilers or dependency management, SCCs represent cyclical dependencies that might need special handling (e.g., mutually recursive modules). In websites or sociology, SCCs can indicate clusters of strongly connected entities (for example, a set of websites that all link to each other, or a tight-knit group of people in a directed friendship/follow graph). Once SCCs are identified, one can analyze the higher-level structure by looking at the DAG of components – for instance, one might collapse each SCC and then perform a topological sort on the component graph to understand overall dependencies between groups. SCC detection is also used in graph algorithms like solving 2-SAT problems (each implication graph of a 2-SAT formula is a directed graph, and the formula is satisfiable if and only if no variable and its negation are in the same SCC).
In summary, graph traversal algorithms like DFS and BFS are fundamental tools that enable us to explore graph data structures. They form the basis for solving more complex problems such as finding shortest paths, detecting cycles, ordering tasks via topological sort, and identifying connected or strongly connected components. Mastering DFS and BFS provides a strong foundation for understanding and implementing a wide range of graph algorithms and for reasoning about graph-structured data in real-world applications.
To go to the main guide about algorithms follow this link: A Friendly Guide to Computer Science Algorithms by Category,