Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

This article will guide and help you explore search methods and algorithms tailored to core data structures: linear & binary scans in arrays, O(1) hash lookups, prefix tries, balanced BSTs, skip lists, and B‑trees, mechanics, trade‑offs, and practical use cases.
The algorithms in our main article about searching algorithms teach you how to search in plain arrays or lists. However, data is often stored in more complex structures that offer their own search mechanisms. These structures are designed to improve search efficiency by storing information in ways that facilitate quick lookups. When you want to search inside one of these structures, you’ll need to use a specialized searching algorithm.
This article is all about searching inside Data Structures. For a more general article about Searching Algorithms, go to the main article: Search Algorithms: A Comprehensive Guide.
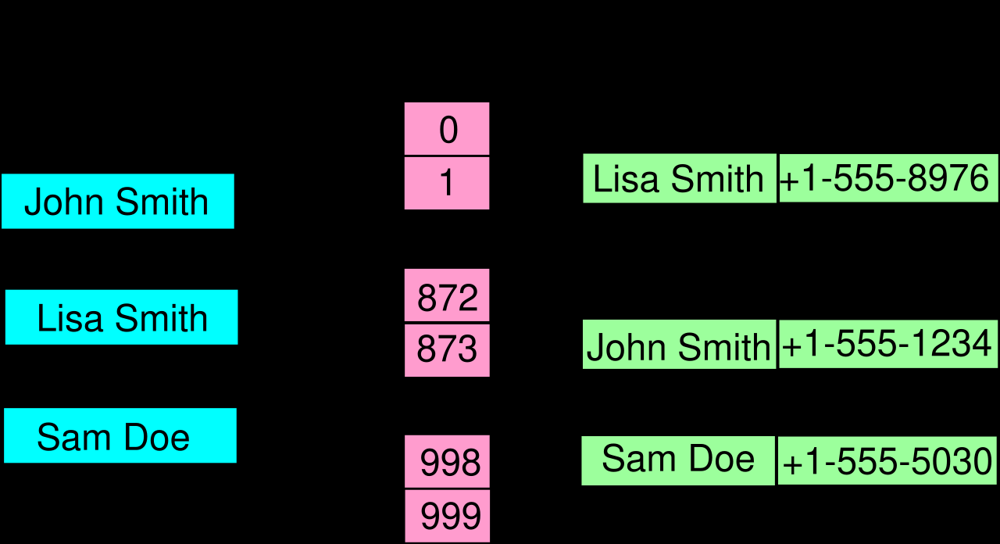
A hash table is a data structure that provides very fast average-case lookup of keys by using a hash function to compute an index. Searching in a hash table involves computing a hash code from the key and then checking the corresponding bucket or slot for the item.
How it works: A hash table maintains an array of “buckets.” When inserting a key (often associated with a value), the key is run through a hash function – an algorithm that deterministically converts the key into a numerical index (usually an integer). This index corresponds to a position in the underlying array. The item is stored in that position. To search for a key, the same hash function is applied to the key, yielding an index; you then look at that index in the array to find the key’s value.
Because different keys can produce the same hash index (a collision), hash tables implement collision resolution strategies:
Time complexity: The power of hash tables is in their average-case performance. A well-implemented hash table offers O(1) average time complexity for search, insertion, and deletion – constant time on average, independent of the number of elements. This assumes a good hash function that distributes keys evenly and that the load factor (ratio of number of entries to number of buckets) is kept in check (often by resizing the table when it becomes too full). In the worst case, however, hash table search can degrade to O(n) time – for instance, if all keys collide into the same bucket, a search might have to scan through all entries in a list.
Use cases: Hash tables are ubiquitous in software development whenever a fast lookup by key is needed:
dict, Java’s HashMap, C++’s unordered_map). This allows quick search of values by keys like strings, identifiers, etc.Hash tables are favored for their average performance and simplicity of use. One must choose a good hash function for the key type to minimize collisions and be mindful of resizing strategies to maintain efficiency. With proper implementation, searching in a hash table is extremely fast and often close to constant time for practical sizes.
A Trie (pronounced “try”, also known as a prefix tree) is a tree-like data structure that is particularly useful for searching strings or sequences by their prefixes. Each node in a trie represents a prefix of some keys, and edges typically correspond to individual characters (or components) of keys.
How it works: In a trie, the root node represents an empty string. Each edge out of the root represents the first character of some keys. As you go down levels, you accumulate characters. Each node may have multiple children, one for each possible next character in keys that share the prefix up to that node. For example, consider a trie storing the words “cat”, “cap”, and “dog”:
To search for a key (e.g., the word “cap”) in a trie, you start at the root and follow the sequence of child pointers corresponding to each character of the key:
Because each step in the search goes to the next character’s node, the time to search is proportional to the length of the key (not the number of keys in the trie).
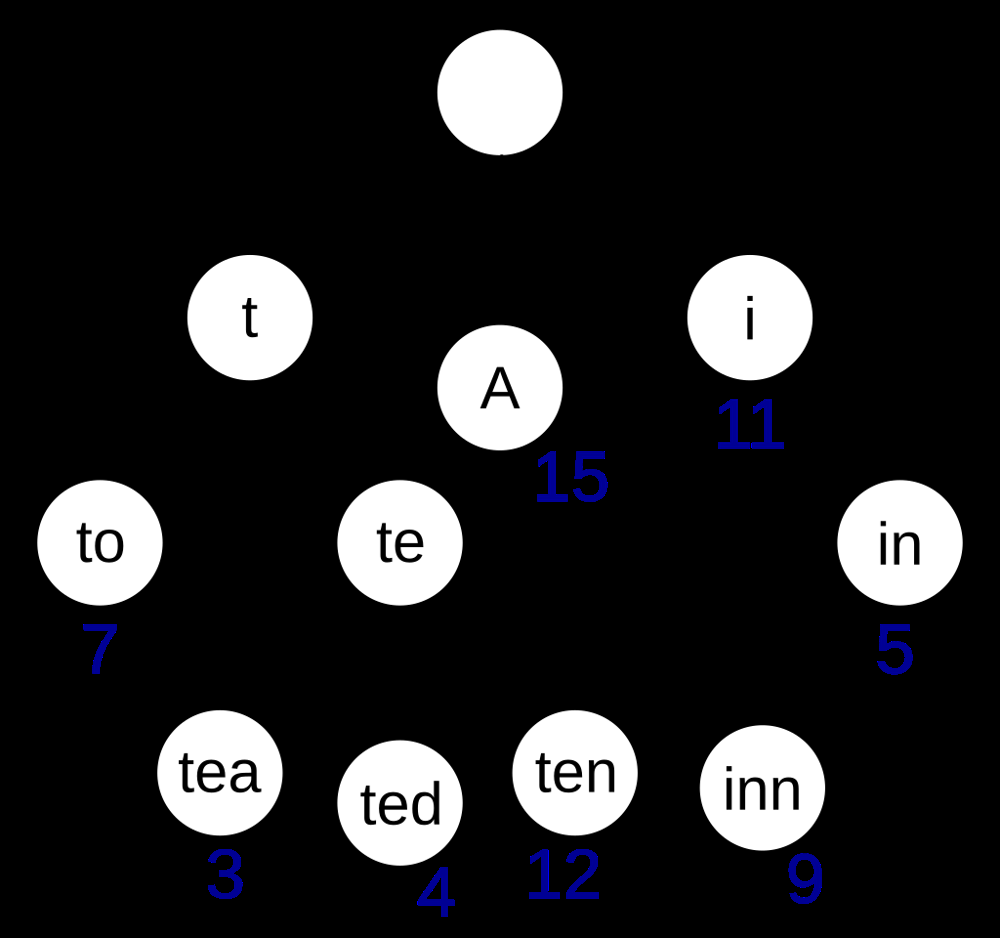
Time complexity: Searching for a key of length m in a trie is O(m) in the worst case. This is independent of how many keys are stored, as it only depends on the length of the key being searched. This makes tries very efficient for search operations, especially when keys are long and share prefixes. In the example above, searching “inn” would take 3 steps (for ‘i’ -> ‘n’ -> ‘n’), regardless of whether the trie stores 10 words or 10 million words, as long as those steps exist. The flip side is space: tries can consume a lot of memory, since they potentially have a node for every prefix of every key, and sparse branches for uncommon prefixes can lead to many null or empty children pointers.
Use cases: Tries are ideal for applications that involve prefix-based searches or need to store a large vocabulary of strings:
While tries excel in speed for searches and prefix operations, they do have overhead in terms of memory. Various optimizations like compressed tries (or radix trees) collapse single-child sequences to save space, and bitwise tries handle binary data efficiently. Nonetheless, the direct character trie is conceptually straightforward and powerful for search tasks where keys have a sequential structure (like strings).
A Binary Search Tree (BST) is a binary tree data structure that keeps elements in sorted order, allowing search, insertion, and deletion operations in average logarithmic time. Each node in a BST has up to two children, often referred to as left and right, and it satisfies the BST property: all nodes in the left subtree of a node have values less than that node’s value, and all nodes in the right subtree have values greater.
How it works: The BST property guides the search algorithm:
This procedure is essentially a binary search performed on the tree structure instead of an array. Each comparison allows the algorithm to discard half of the remaining tree (all nodes on one side).
For example, consider a BST containing the numbers 8, 3, 10, 1, 6, 14, 4, 7, 13 (inserted in that order). The BST might be structured with 8 at the root, 3 as left child of 8, 10 as right child of 8, and so forth (3’s left child 1, 3’s right child 6, etc.). If we search for the value 7:
Time complexity: The time complexity for search (and insert/delete) in a BST is O(h), where h is the height of the tree. In a balanced BST, the height h is O(log n) for n nodes, so searches take O(log n) on average. However, in the worst case, if the tree becomes skewed (like a linked list – which can happen if we insert already sorted data into an unbalanced BST), the height becomes O(n) and search time degrades to O(n).
Balanced binary search trees (like AVL trees, Red-Black trees, B-Trees, etc.) have extra rules or rotations to keep the height minimal, ensuring consistently good performance. Many library implementations of sets and maps are backed by balanced BSTs (e.g., C++ std::map typically uses a Red-Black tree).
Use cases: BSTs are useful when you need to maintain a dynamically changing set of comparable items and be able to search, insert, and delete efficiently:
One important advantage of BSTs over hash tables is that BSTs maintain elements in sorted order, so you can perform range queries (find all entries between X and Y) efficiently by traversing the tree – something not directly possible with hash tables. Balanced BSTs guarantee that the performance remains good even in the worst case, making them reliable for applications requiring consistent responsiveness.
For more search algorithms and techniques please go back to the main article: Search Algorithms: A Comprehensive Guide.